Modifying files in python
Simple text files like parameters.txt
1P1=5
2P2=17
3P5=12
can easily be read ("r") via
with open("parameters.txt", "r") as prm_file:
for line in prm_file:
name, value = line.split("=")
if name == "P2":
print("[parameters.txt] value of P2 is", float(value))
Other file formats like YAML or
JSON offer a more convenient access. For example, modifying the parameters.yaml
1Material parameters:
2 E:
3 name: "Young's modulus"
4 value: 20000.
5 unit: "MPa"
6 nu:
7 name: "Poission's ratio"
8 value: 0.2
9 unit: "-"
10 ft:
11 name: "tensile strength"
12 value: 4.
13 unit: "MPa"
14
15Simulation parameters:
16 dt:
17 name: "time increment"
18 value: 0.1
19 unit: "s"
20
requires pip3 install pyyaml and is done by
import yaml
with open("parameters.yaml", "r") as prm_file:
prm = yaml.load(prm_file, Loader=yaml.FullLoader)
prm_E = prm["Material parameters"]["E"]
assert prm_E["unit"] == "MPa"
print("[parameters.yaml] value of E is", prm_E["value"])
Writing YAML is done via
prm_E["value"] = 17840.2
with open("parameters_modified.yaml", "w") as prm_file:
yaml.dump(prm, prm_file)
1Material parameters:
2 E:
3 name: Young's modulus
4 unit: MPa
5 value: 17840.2
6 ft:
7 name: tensile strength
8 unit: MPa
9 value: 4.0
10 nu:
11 name: Poission's ratio
12 unit: '-'
13 value: 0.2
14Simulation parameters:
15 dt:
16 name: time increment
17 unit: s
18 value: 0.1
Interacting with MS Excel
A popular package that provides a pythonic representation of MS Excel workbooks/worksheets is openpyxl.
> pip3 install openpyxl
Open a worksheet
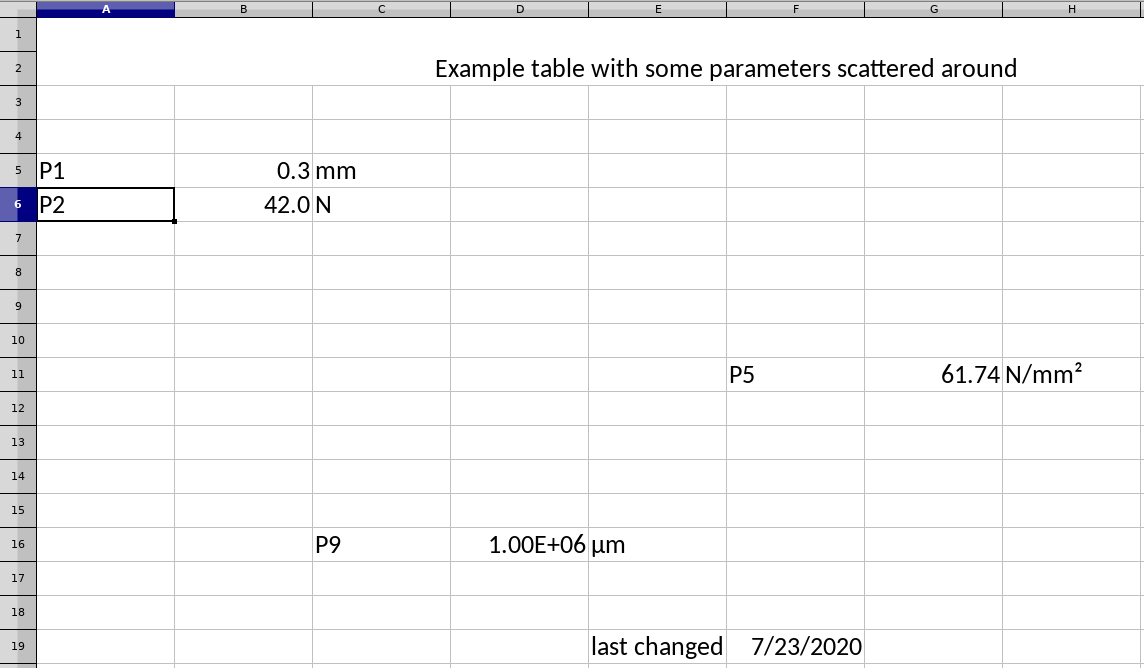
import openpyxl
workbook = openpyxl.load_workbook("parameters.xlsx")
worksheet = workbook.active
you can also select the worksheet by name
worksheet_by_name = workbook["Tabelle1"]
assert worksheet == worksheet_by_name
Reading from a worksheet
You can either access cells by name …
print("Cell A6 contains:", worksheet["A6"].value)
… or by index.
print("Cell (6,1) contains:", worksheet.cell(6, 1).value)
assert worksheet["A6"].value is not None
assert worksheet["A6"] == worksheet.cell(6, 1)
Note that openpyxl uses one-based-indexing. So in contrast to python lists or
numpy, where the first entry is list[0] or numpy.array[0,0], the first
cell in the worksheet is cell(1,1).
Openpyxl lets you conveniently loop through the cells of the worksheet, e.g. to find the cell that containts “P2” and to access its right neighbor.
for row in worksheet:
for cell in row:
if cell.value == "P2":
i, j = cell.row, cell.column
print("Found P2 at cell:", i, j)
print("Cell right of P2 has value:", worksheet.cell(i, j + 1).value)
Modifying a worksheet
Similar to reading cells, you can assign values by name or index.
worksheet["B11"] = "P_new"
worksheet["C11"] = 17.0
assert worksheet.cell(11, 3).value == 17.0 # C-->3
worksheet.cell(11, 3).value = 6174.0
Don’t forget to save the modified workbook.
workbook.save("parameters_modified.xlsx")
Use cases
You can now get creative and write a function that finds the position of a string within a worksheet …
def row_col_of(ws, parameter_name):
for row in ws:
for cell in row:
if cell.value == parameter_name:
return cell.row, cell.column
raise RuntimeError(f'There is no cell containing "{parameter_name}" in {ws}.')
… to extract parameter values from the worksheet …
i, j = row_col_of(worksheet, "P2")
P2_value = worksheet.cell(i, j + 1).value
and write it to a different file, e.g. by replacing a known placeholder with
the value. We therefore load a base_input_file.dat (containing the placeholders),
1* This is a made-up input file for the
2* Tool <ANSYS, ABACUS, you name it...>
3* that contains some fixed parameters,
4* and some that can be defined within
5* a workflow.
6
7MESH = "bridge_fine.xdmf";
8E = 20000.0;
9nu = 0.3;
10P2 = P2_PLACEHOLDER;
11delta_t = 0.1;
12boundary = "periodic";
13
14...
replace the placeholder with our value from the Excel sheet and save it to a different file.
s = open("base_input_file.dat", "r").read()
s_modified = s.replace("P2_PLACEHOLDER", str(P2_value))
open("input_file_modified.dat", "w").write(s_modified)
Further reading
Basic web searches like
“python read file”
“python loop through file line by line”
“python replace string in file”
…
will often lead you to stackoverflow.com
are often faster than reading whole tutorials
can result in ugly code, but that is OK.
Interacting with MS Word
One use case in reproducible science that works great in the context of LaTeX files is the separation of text and images, where the images are generated automatically in separate workflows. For MS Word, the challenge is to update images of a document automatically.
A MS Word document is basically a zip file containing a text layer and a picture layer. Those pictures are, if unzipped, stored in word/media and can be accessed via
import zipfile
z = zipfile.ZipFile("report.docx")
all_files = z.namelist()
images = [f for f in all_files if f.startswith("word/media/")]
print(images)
You can now modify the contents (actually creating a new zip file) to replace
one of the images with another one. This is conveniently done by the provided
class UpdatableZipFile (web search: python replace file in zip lead to
https://stackoverflow.com/a/35435548 )
You can direcly overwrite the report.docx, but we chose to work on a copy of it (report_modified.docx) here.
from updateable_zip_file import *
shutil.copy("report.docx", "report_modified.docx")
new_images = [ # order matters!
"dummy_images/red.png",
"dummy_images/blue.png",
"dummy_images/gray.png",
"dummy_images/green.png",
]
with UpdateableZipFile("report_modified.docx", "a") as o:
for new, old in zip(new_images, images):
o.write(new, old)
The big inconvenience is that you cannot recover the image names from the *.docx file, so you have to rely on the ordering.
Comment (TTitscher): As the MS Excel/Word is not part of my daily work, I have no experience how the methods above perform in practice. However, I believe that this topic is important and I suggest forming a working group (lead by someone else) that investigates the methods further.